机器学习分类算法
分类(Categorization or Classification)是根据已知训练样本,通过计算选择特征参数,建立判别函数以对样本进行的分类,属于监督学习范畴。分类算法的核心就是按照某种标准给对象贴标签(label),再根据标签来区分归类。 常用的多分类算法包括Adaboost,决策树,随机森林以及线性支持向量机等,其中:(1)Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器); (2)决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法; (3)随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定; (4)支持向量机方法是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折中,以求获得最好的推广能力。 该模块提供了分类算法有Adaboost,决策树,随机森林以及线性支持向量机等分类算法,通过输入训练集与标签,在选择好算法后点击训练模型对模型进行训练,并输出准确率,
具体步骤如下:
1.导入数据格式
点击导入数据,并将存于txt中的数据与对应的标签导入到下方的空格中。也可以通过手动输入的方式添加数据以及标签。导入的数据要求为txt,每行上的数据都以逗号隔开,其中最后一列数据为数据的标签,一般以整数数据代表不同的标签,导入数据的格式如下图所示:

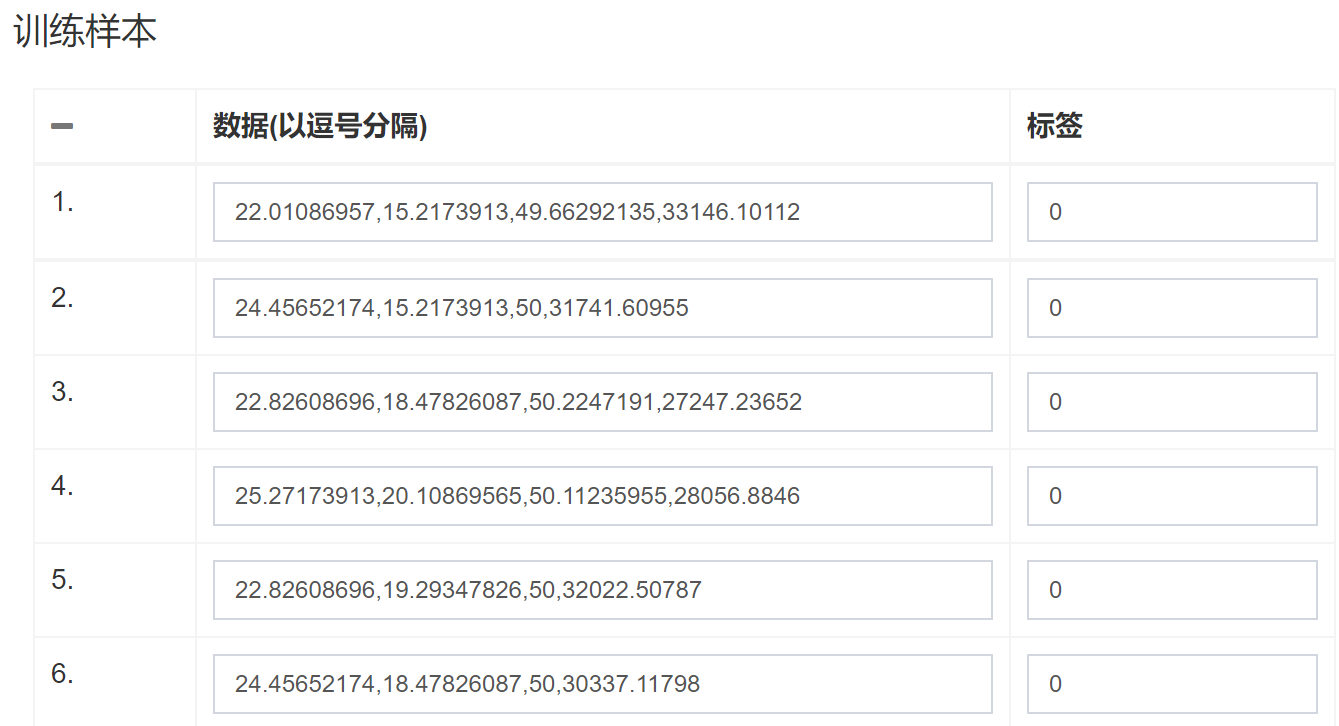
2. 导入训练样本
在训练样本处,点击“导入数据”,导入txt格式的训练样本文件。 导入前如下图所示:
导入后的训练样本如下图所示:
3. 导入测试样本
在测试样本处,点击“导入数据”,导入txt格式的测试样本文件。 导入前如下图所示:
导入后如下图所示:
可以通过点击加号来查看导入的数据:
4. 选择分类算法并训练模型
从分类算法下拉中选择需要使用的算法,然后点击“训练模型”,即得到训练结果。
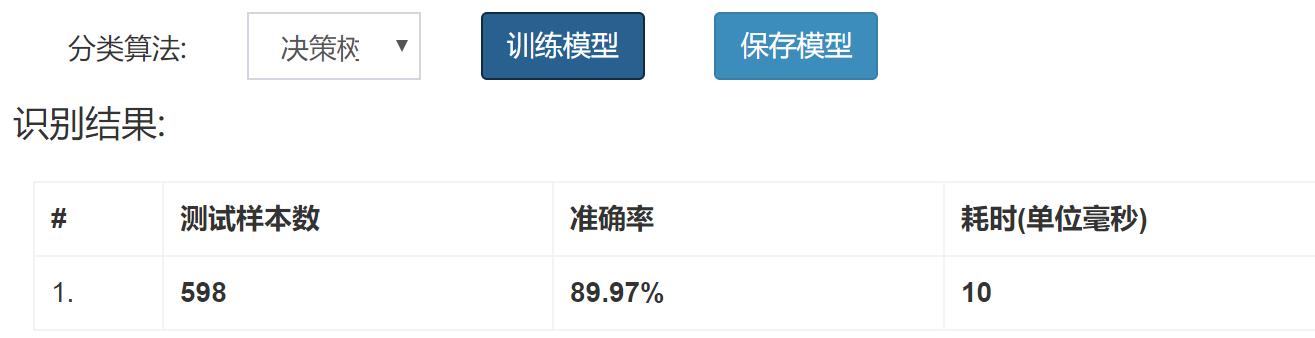
得到的模型预测结果将显示在下方:
也可点击保存模型,将训练好的模型保存。
识别结果:
| # | 测试样本数 | 准确率 | 耗时(单位毫秒) |
|---|---|---|---|
| 1. |