机器学习聚类算法
聚类分析又称群分析,是研究(样品或指标)分类问题的一种统计分析方法,同时也是数据挖掘的一种重要的无监督算法,能够挖掘数据之间的内在性质和规律,可以将数据点归结为一系列特定的组合。理论上归为一类的数据点具有相同的特性,而不同类别的数据点则具有各不相同的属性(物以类聚,人以群分)。在数据科学中聚类会从数据中发掘出很多分析和理解的视角,让我们更深入的把握数据资源的价值、并据此指导生产生活。
计算步骤
① 导入数据准备:
导入的数据要求为txt,每行上的数据都以“,”隔开,导入数据格式如图1:
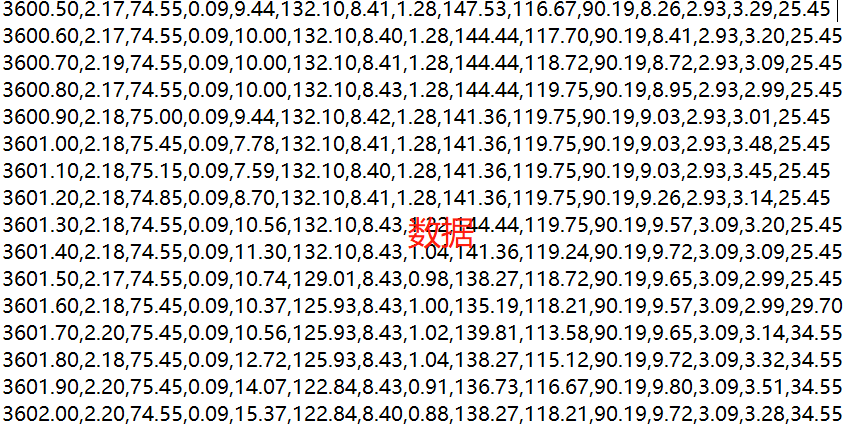
图1 导入数据格式
② 导入数据
点击“导入数据”,导入txt格式的数据。导入前如图2:

图2 数据导入前界面
数据导入后界面如图3所示:

图3 数据导入界面
数据导入后可以看到成功导入数据的行数,点击“+”可以查看,如图4:
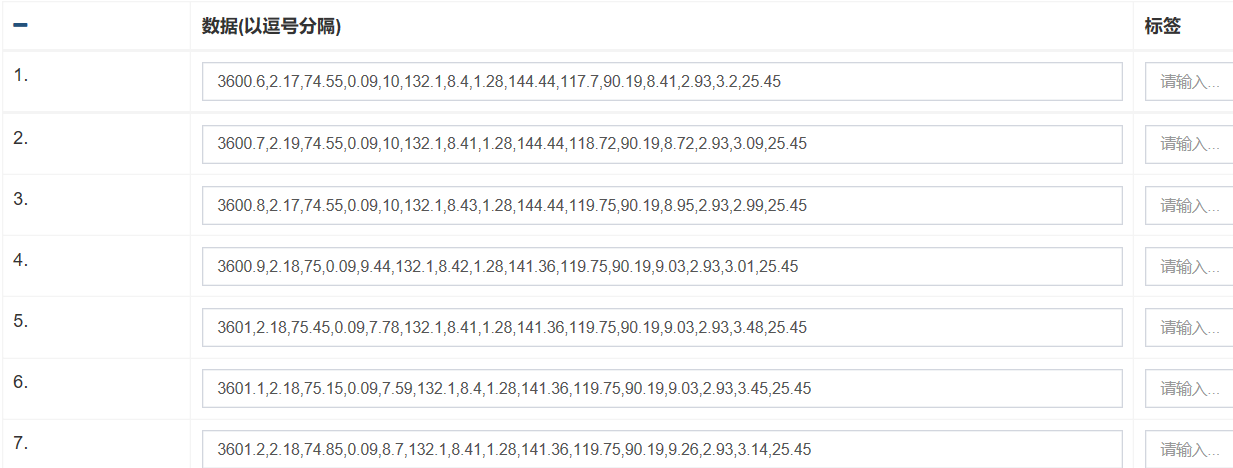
图4 查看导入数据界面
③ 选择聚类算法
选择聚类算法如图5所示
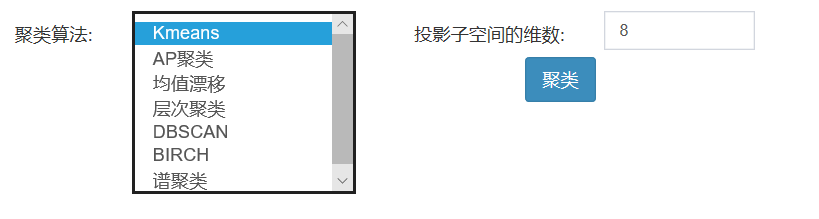
图5 聚类算法选择图
④ 点击“聚类”,得到识别结果如图6:

图6 识别结果显示
⑤ 导出
点击“导出数据”,可导出数据对应的标签。同时,也可通过导入界面查看标签输出情况,如下图所示:

识别结果:
| # | 结果 | 耗时(单位毫秒) |
|---|---|---|
| 1. |